Additional Information
This issue is better known as TDMS fragmentation. Any time data is written to a TDMS file, a metadata header is written along with the data to the TDMS index file. This means if you write 1 point at a time to the TDMS file, there is header information for every data point in your file. With the code included below, metadata is written each time we use
TDMS Write Function to write Time and Chn1 data each iteration of the loop.
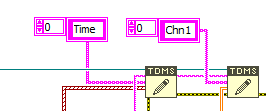
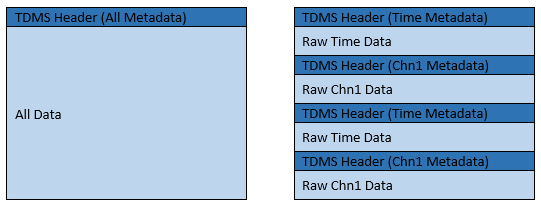
To minimize this effect, it is recommended that users write multiple data points at once to the TDMS file, or you can use one of the built-in TDMS functions.
The
TDMS Defragment Function will go through the current TDMS file and consolidate all data dealing with a particular channel. It does take some time to run a large TDMS file through the
TDMS Defragment Function, but it will speed up performance for subsequent TDMS reads. When opening the file in DIAdem, this also defragments the file and consolidates all metadata. Both of these create an index file to defragment the file even if the Open TDMS function is set to not create an index file.
The last option is to use a buffer to store a certain amount of data before being written to the TDMS file. If you are only writing one point of data per TDMS Write in your code then you can specify a minimum buffer size that must be achieved before anything will get written to the TDMS file. This will decrease the number of headers being written, which will also speed up performance. To accomplish this, use the TDMS Set Properties.vi to set the NI_MinimumBufferSize to a desired value for every channel being written to the TDMS file. You can find the steps to set the minimum buffer size on the following LabVIEW Help page:
File Buffering with TDMS Files.